

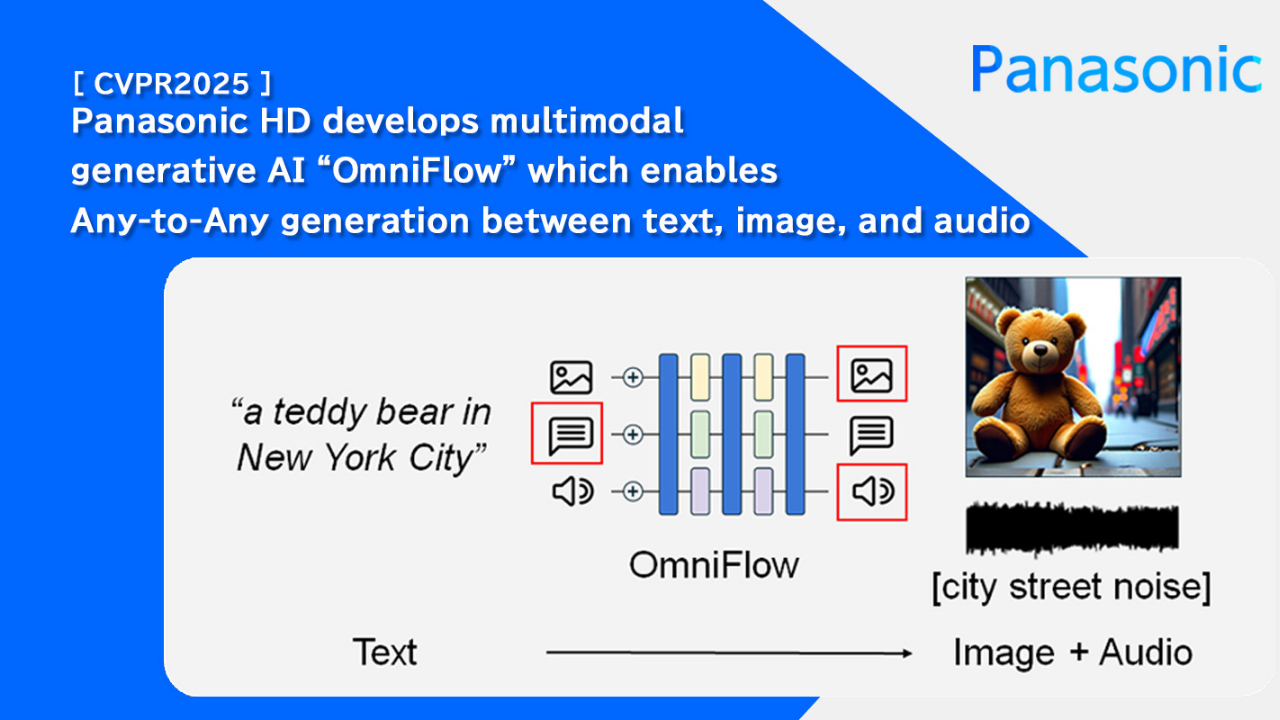
Panasonic Holdings Co., Ltd. (Panasonic HD), in collaboration with Panasonic R&D Company of America (PRDCA), has developed OmniFlow—a multimodal generative AI capable of seamlessly converting between text, image, and audio formats. The development also saw close collaboration with the researchers from the University of California, Los Angeles (UCLA).
OmniFlow integrates generative AI models specialized for each data format, enabling it to learn high-precision Any-to-Any transformations even from limited datasets that include all three modalities. OmniFlow builds on image generation flow matching to capture complex relationships by connecting and processing features from three different data types during generation.
Shows Best Performance
In evaluation experiments, OmniFlow outperformed both specialized and generalist models in “text-to-image” and “text-to-audio” tasks, demonstrating best-in-class performance across methods. The experiments also found that the data size required to train OmniFlow can be reduced to up to 1/60 compared to any other any-to-any method.
Future Applications
OmniFlow is a flexible, any-to-any AI that delivers high accuracy even with limited training data across text, image, and audio. Its adaptability makes it ideal for applications in diverse fields like manufacturing and daily life, expanding multimodal AI’s potential.
OmniFlow to Shine at CVPR
This advanced technology has gained global acclaim and has been accepted at the 2025 Conference on Computer Vision and Pattern Recognition (CVPR 2025), a premier AI and computer vision conference. It will be showcased at the upcoming plenary session in Nashville, USA, from June 11 to 15, 2025.
